Since OLE Nepal’s inception in 2007 we have strived to provide open and free access to quality education and innovative learning environments to children all over Nepal. One of our core missions is to reduce the disparity found within the accessibility of learning tools brought about by geographic location, school type, and population group. E-Pustakalaya, our free and open digital library, closed the gap by providing a collection of thousands of books, educational resources, course content, and reference materials directly to students and educators. Not only did this library aid in providing quality educational content, it has aided in the development of reading habits early on and has sparked an inquisitive nature within students by providing the means to conduct independent research.
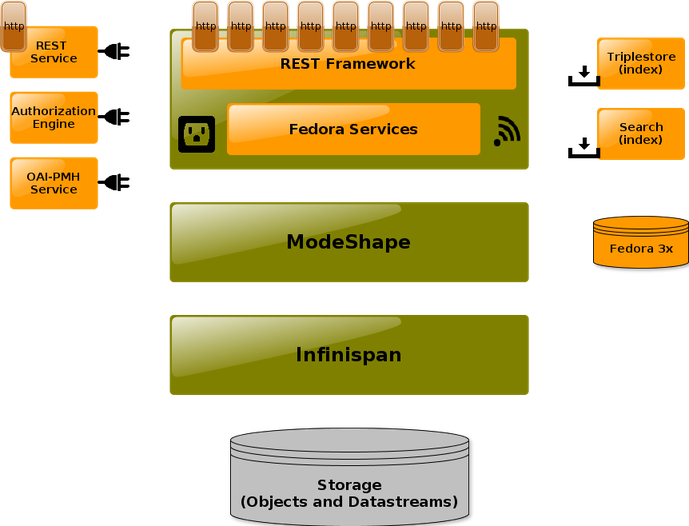
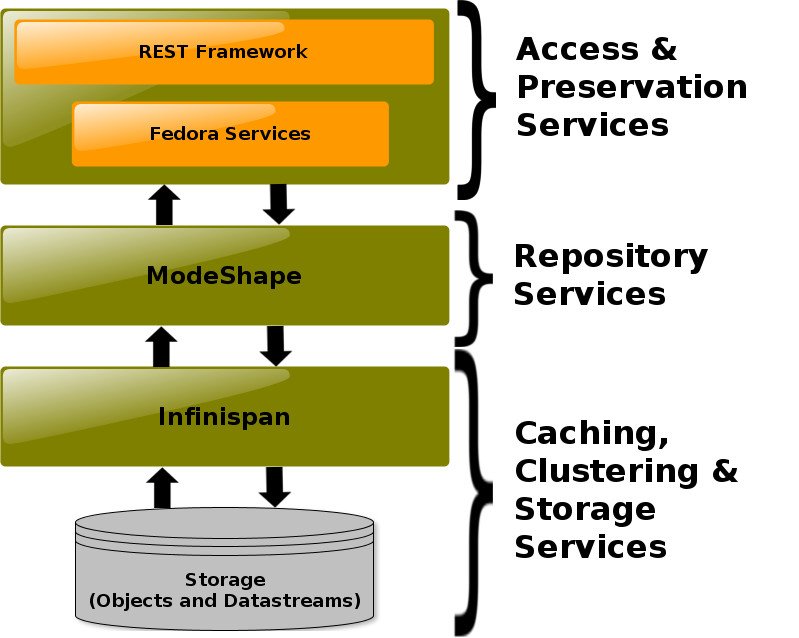
The initial iteration of E-pustakalaya utilizes FEDORA (an acronym for Flexible Extensible Digital Object Repository Architecture), a digital object repository architecture designed to achieve scalability, stability, flexibility and extensibility, while at the same time providing for interoperability between systems. FEDORA is positioned within a larger open-architecture framework in which the total functionality of a digital library is partitioned into a set of services with well-defined interfaces described in the image below.
 |
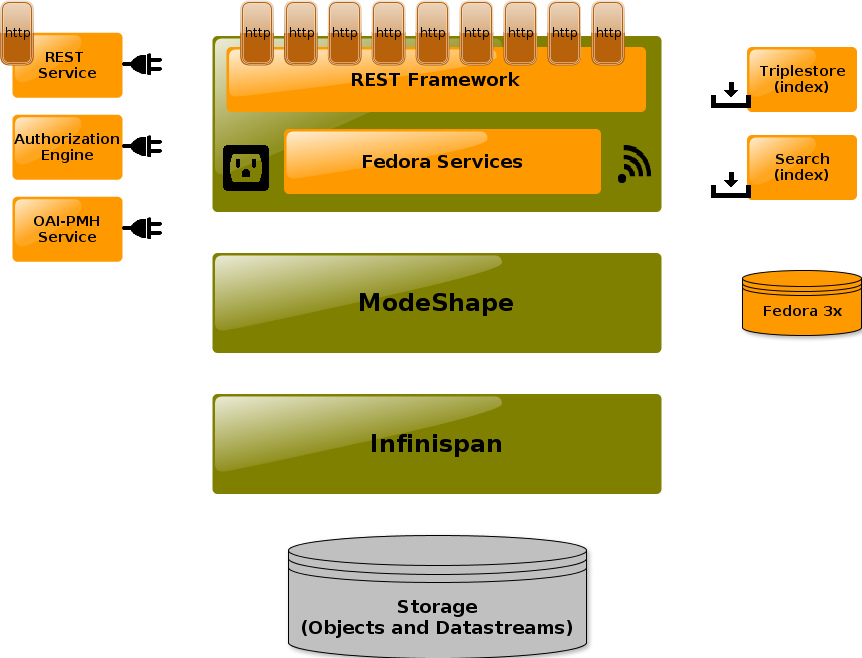 |
Fedora Commons is developed on the top of a Java application and is popularly deployed through Tomcat. The front-end interface and querying of items in Fedora Commons is handled by FEZ and PHP. Currently we are using Fedora Commons 2.2 deployed in Tomcat 4.1.12 and Java 6. We have tinkered CentOS 6.4 to orchestrate the deployment.
It has been over eight years since E-Pustakalaya’s initial launch and we are currently in development of a new E-Pustakalaya powered by DSpace: an open source repository software originally written by MIT and HP Labs and is currently developed by DuraSpace. The main reasons for our switch are as follows:
1) The Lack of Support for FEZ and front-end responsiveness
The FEZ interface is currently being loosely maintained at Github and lacks the proper support and documentation we require for the expansion of features like document streaming or a responsive interface.
2) We wanted a more optimized database
Within the old E-Pustakalaya we utilized PHP to directly query for the desired items and their metadata within a relational database. These queries eventually proved inefficient as several parts had to be queried from a relational database of millions of items that did not have a back-end search engine that provided an inverted index like Solr.
3) DSpace showed up with all the solutions
We chose DSpace because it met the standards of scalability, flexibility, and stability we set for the previous iteration of E-Pustakalaya, while also providing a greater environment for the expansion of features. It provided a robust front-end interface that supported the implementation of the responsiveness that we sought for and had a sophisticated querying system that could handle our immense library. DSpace also allowed for the same wide range of file formats to cover educational content from books, videos, and recordings.
Now within the library are millions of items of various file formats. DSpace records the metadata for these items and then the file formats are converted into bitstreams. The meta data and bitstreams are tied to the item which then gets grouped into a designated collection. These collections are then organized into general communities. Take for instance a community was labeled “Literature,” within this community some example collections could be the genres within literature, for instance: fiction, nonfiction, or children’s books. Within these collections the books would be the items and the metadata would hold various recording information like the authors, release dates, and other descriptive information.
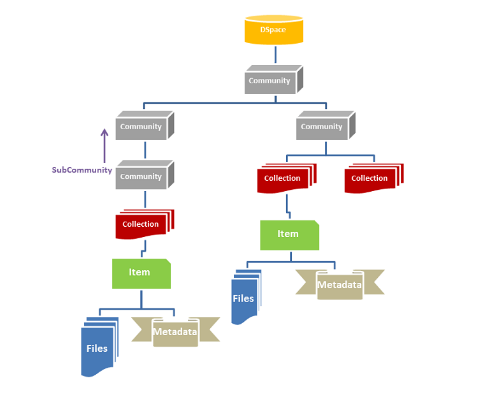
To query these items from the collections or communities, DSpace utilizes Solr Discovery to facilitate faceting and search result filtering. Solr provides the inverted index to provide speedy access to content metadata and data while simultaneously recording usage statistics. To carry out these tasks DSpace has a multicore setup of Solr which includes a “search core” that deals with the data about the communities, collections, and items, and a “statistics core” that deals with view counts, searches, and user data. The search core effectively finds the item with its indexing and then queries for the relevant bitstreams tied to the item within a Postgresql database. Solr also allows us to create custom metadata which helps its effectiveness in indexing. The interaction between Solr querying and the traditional Postgresql database facilitates the fast querying and filtering of items while only querying for relevant bitstreams from a relational database.
The front-end web interface of the new E-Pustakalaya is generated through XMLUI and is based on Apache Cocoon, which primarily utilizes Java, XML, and XSLT. We have heavily customized the original Mirage2 theme to match the end product designs that were decided upon by OLE designers. Through Apache Cocoon each page is created through a pipeline where every aspect is “added” to the page separately and work independently from each other. We have customized the built-in aspects to provide the desired document streaming for books, audio files, and video files. This is accomplished by incorporating open source add-ons like pdf.js and video.js which are HTML5 based interfaces that we provide within the server so that the end-user can access the educational content directly, without the need to install plugins within their browser. We have also added a commenting feature using Disqus so users have the ability to comment on each item, which can facilitate discussions between students and educators.
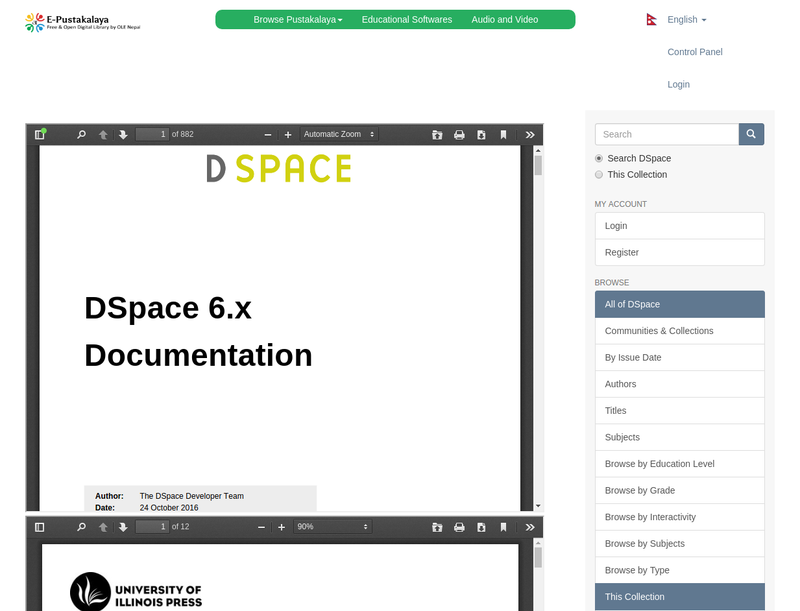
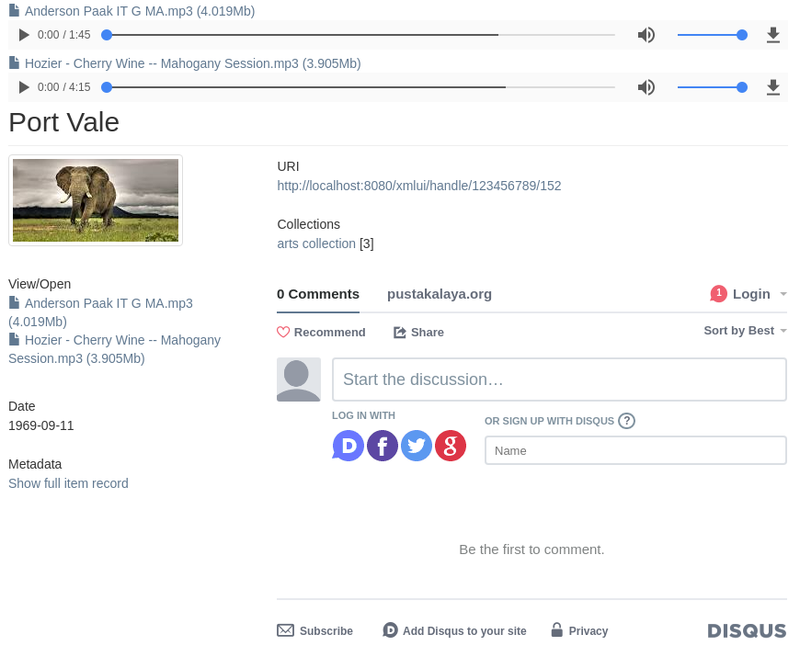
Overall DSpace provides an extremely robust and flexible database that can handle virtually any file format that we would ever need. Its use of Solr Discovery makes queries fast, reliable, and highly customizable. An upgrade from the previous database which utilized PHP to run queries from a SQL database. Even on the front-end the aspect style formatting of features allows us to freely customize specific aspects without the worry of affecting another feature.
Our development team, consisting of a systems engineer, a software developer, and a development intern, is relatively small given the scale of the project. DSpace out of the box did not natively support many of the features already adopted within our own repository. For instance, the aforementioned document streaming modules are built up of third party add-ons; pdf.js provides the module for viewing pdf files and video.js provides the modules for streaming any file format compatible with HTML5. Video.js actually grants us with a high level of flexibility on which file formats we can use for videos and recordings, but for now, we have chosen to stick with mp4 and mp3, for video and audio respectively, as they are widely used and are compatible with almost all browsers.
DSpace’s ability to use Solr Discovery is heavily reliant on the metadata tied to the items as these are how items and their bitstreams are easily indexed and queried. The process of transferring items from the previous data base might have to be done manually as the formats of the databases do not currently provide an obvious solution for their automatic transfer. We have discussed plans on tiered transitions where we would transfer over parts of the database at a time rather than a full-scale transition. We will of course also be looking into how we can automate some of the processes for the eventual transition.
There is also the challenge of localization and maintenance. Since OLE is planning on distributing this library format to remote villages in Nepal; access to the internet may not be possible and some features of the repository may require an internet connection to work such as the commenting features in Disqus. There is also the somewhat steep learning curve of customizing the XMLUI interface as it is based on XML, XSLT, CSS, and Java which would require a working understanding of those languages for any form of customization. We have talked about writing a comprehensive guide on the customization of popular features in the repository and to also provide references to the original DSpace documentation if further customization is desired.
As of writing this blog, the team is still currently in development of the new E-Pustakalaya and is making steady progress towards the end goal of providing a necessary platform to bridge the gap on the accessibility of quality educational content. The current local instance of the E-Pustakalaya has the core database established that allows for multiple file streaming on a vibrant, newly designed web interface. The whole team is very excited about continuing in the development of the new E-Pustakalaya and is enthusiastic about what the end product can help achieve.